Human Robot Interaction
Human-Robot Interaction (HRI) refers to the study and design of interactions between humans and robots. It encompasses the development of technologies, interfaces, and systems that enable effective communication, collaboration, and cooperation between humans and robots. HRI aims to create intuitive and natural ways for humans to interact with robots, allowing for seamless integration of robots into various domains such as healthcare, manufacturing, entertainment, and personal assistance.
HRI Overview
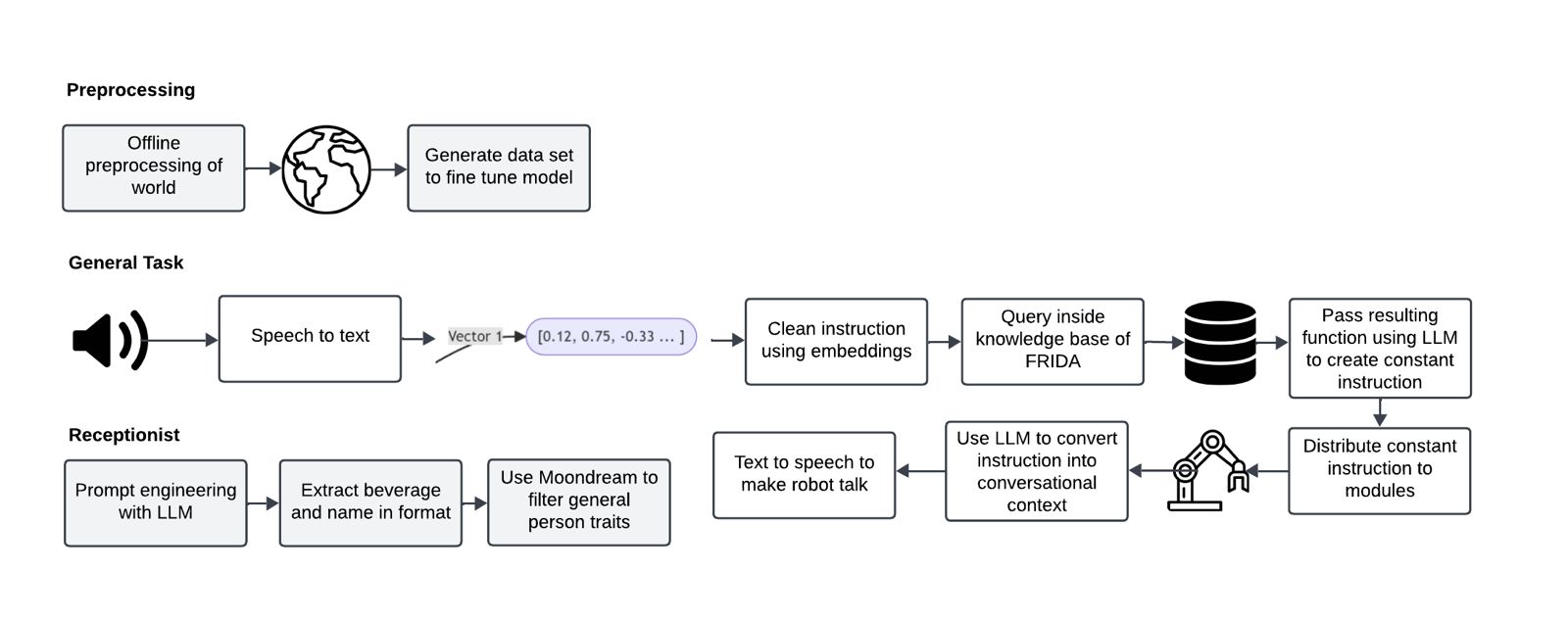
Currently, in RoBorregos, the development of HRI consists of 2 pipelines: speech and NLP processing. The speech pipeline has several modules to achieve robustness while being computationally efficient (i.e. ensure resource-intensive models only infer voiced audio). The first module of speech is the Keyword Spotting node, which was implemented using porcupine. After the keyword is detected, audio is recorded until voice is no longer detected using Silero VAD. The audio captured is then inferred using Whisper.
Finally, the NLP pipeline processes the interpreted text by parsing the string into commands using an LLM. As a strategy to deal with malformed LLM outputs, the resulting commands are matched to the closest valid action according to the robot context and capabilities, found via cosine similarity by embedding the actions if there is no exact match.
ROS Nodes Documentation
This document provides detailed documentation on the ROS nodes, their purpose, and usage. It covers all the ROS nodes and their tasks, providing comprehensive instructions for running the system.
ROS Nodes in ws/src/frida_language_processing/scripts
command_interpreter_v2.py
- Purpose: This node interprets commands from the user.
- Usage:
- Subscribes to:
/speech/raw_command - Publishes to:
/task_manager/commands - Description: This node uses OpenAI's GPT-4 model to interpret commands received from the speech processing and sends the actions to the Task Manager.
conversation.py
- Purpose: This node handles conversational interactions with the user.
- Usage:
- Subscribes to:
/speech/raw_command - Publishes to:
/speech/speak - Description: This node stores context from the environment, previous prompts, and user interactions to provide accurate and conversational responses.
guest_analyzer.py
- Purpose: This node analyzes guest information.
- Usage:
- Subscribes to:
/speech/raw_command - Publishes to:
/speech/speak - Description: This node extracts information from the guest for the Receptionist task of Stage 1.
extract_data.py
- Purpose: This node extracts data for processing.
- Usage:
- Provides service:
/extract_data - Description: This node extracts structured data including summary, keywords, and important points from text.
item_categorization.py
- Purpose: This node classifies text data of images and groups them.
- Usage:
- Provides service:
items_category - Description: This node returns the category of an item or list of items for the Storing groceries task.
ROS Nodes in ws/src/speech/scripts
AudioCapturer.py
- Purpose: This node captures audio from the microphone.
- Usage:
- Publishes to:
rawAudioChunk - Description: This node captures audio from the microphone and publishes it as raw audio chunks.
Say.py
- Purpose: This node handles text-to-speech functionality.
- Usage:
- Subscribes to:
/speech/speak_now - Provides service:
/speech/speak - Description: This node converts text to speech using either an online or offline TTS engine.
ReSpeaker.py
- Purpose: This node interfaces with the ReSpeaker hardware.
- Usage:
- Publishes to:
DOA - Subscribes to:
ReSpeaker/light - Description: This node interfaces with the ReSpeaker hardware to get the direction of arrival (DOA) of sound and control the LED ring.
KWS.py
- Purpose: This node handles keyword spotting.
- Usage:
- Subscribes to:
rawAudioChunk - Publishes to:
keyword_detected - Description: This node uses Porcupine to detect keywords in the audio stream.
UsefulAudio.py
- Purpose: This node processes useful audio segments.
- Usage:
- Subscribes to:
rawAudioChunk,saying,keyword_detected - Publishes to:
UsefulAudio - Description: This node processes audio segments to determine if they contain useful speech and publishes the useful audio.
Hear.py
- Purpose: This node handles speech-to-text functionality.
- Usage:
- Subscribes to:
UsefulAudio - Publishes to:
UsefulAudioAzure,UsefulAudioWhisper - Description: This node converts speech to text using either an online or offline STT engine.
Whisper.py
- Purpose: This node processes audio using the Whisper model.
- Usage:
- Subscribes to:
UsefulAudioWhisper - Publishes to:
/speech/raw_command - Provides service:
/speech/service/raw_command - Description: This node uses the Whisper model to transcribe audio to text.
Comprehensive Instructions for Running the System
-
Setup Docker:
-
Follow the instructions in
docker/README.mdto set up Docker and create the necessary containers. -
Build the Workspace:
-
Inside the Docker container, navigate to the workspace directory and build the workspace:
-
Run the ROS Nodes:
-
To run the speech nodes:
-
To run the language processing nodes:
-
Test the System:
-
To test the text-to-speech functionality:
-
To test the command interpreter:
-
Debugging:
- Use
rostopic echoto listen to the topics and verify the messages being published. - Check the logs for any errors or warnings.
By following these instructions, you should be able to set up and run the ROS nodes for the Human-Robot Interaction system.