Computer Vision
This module focuses on two main areas: Human Analysis and Object Detection, obtaining images from a Stereolabs ZED2. Additionally, this year we also explored Visual-Language Models (VLMs) to enhance our capabilities in understanding visual content. To check the current architecture, check the Vision Architecture document.
Human Analysis
This subarea focuses on analyzing human features and behaviors using computer vision techniques. Some of the main tasks include:
- Recognizing faces
- Tracking persons and re-identifying them across different frames
- Detecting poses and gestures
- Identifying combination of clothes and colors
- Describing a person
Object Detection
The main objective of this subarea is the dataset generation pipeline used to train a YOLO model. However it also includes the integration of zero-shot models or other alternatives as a plan B for object detection. Additionally, this year an alternative to shelf level detection was explored using mainly opencv.
VLM
This subarea explores visual-language models (VLMs) to enhance the understanding of visual content in conjunction with language processing. Currently, the team uses the model moondream for image prompting.
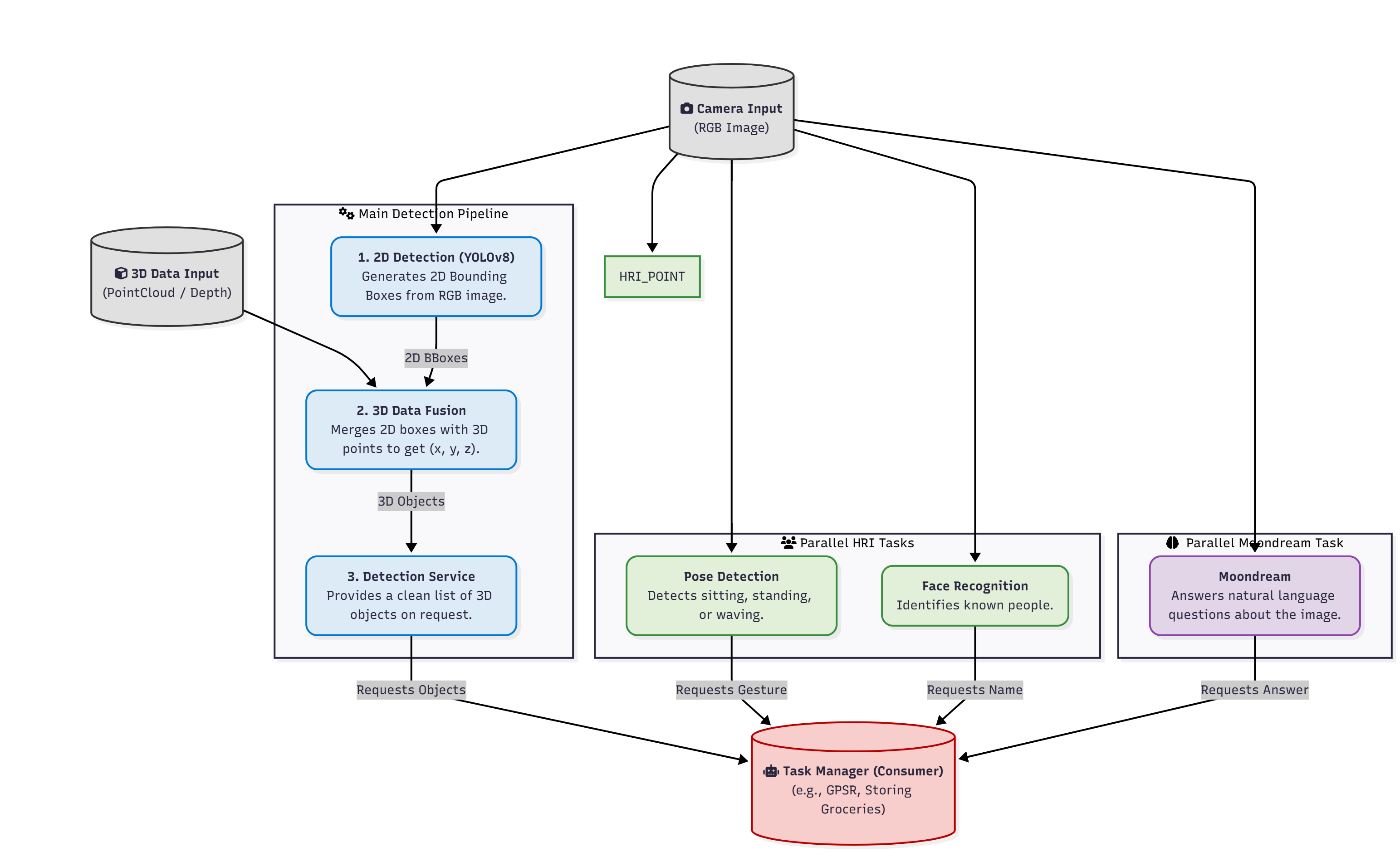
General pipeline
The following diagram provides an overview of the vision pipeline, illustrating how visual data from the ZED camera is processed through interconnected subsystems for human analysis, object detection, and visual–language understanding. The information produced by these subsystems is fused to generate a structured representation of the environment, enabling interaction and high-level decision-making in a home setting.
Running vision
For details on how to run the vision module, check the home repo: Run Vision